🔧 MLOps / GPU虚拟化与调度 / 云边端一体化平台
产品介绍
行智·协同式AI全栈开发平台是数之联推出的面向开发者的 AI 全栈开发平台,支持多人协同,提供完整的知识发现和应用流程。平台为用户提供数据管理、数据标注、算法管理、训练管理、模型管理、在线评估及模型按需部署能力,实现 AI 开发全周期管理。基于行智 AI 平台,用户无需编码,即可基于简单的可视化页面完成从数据到上层应用的构建。
产品来源:https://www.unionbigdata.com/ProductDetail/10145059.html - 《行智·协同式AI全栈开发平台》
项目简介
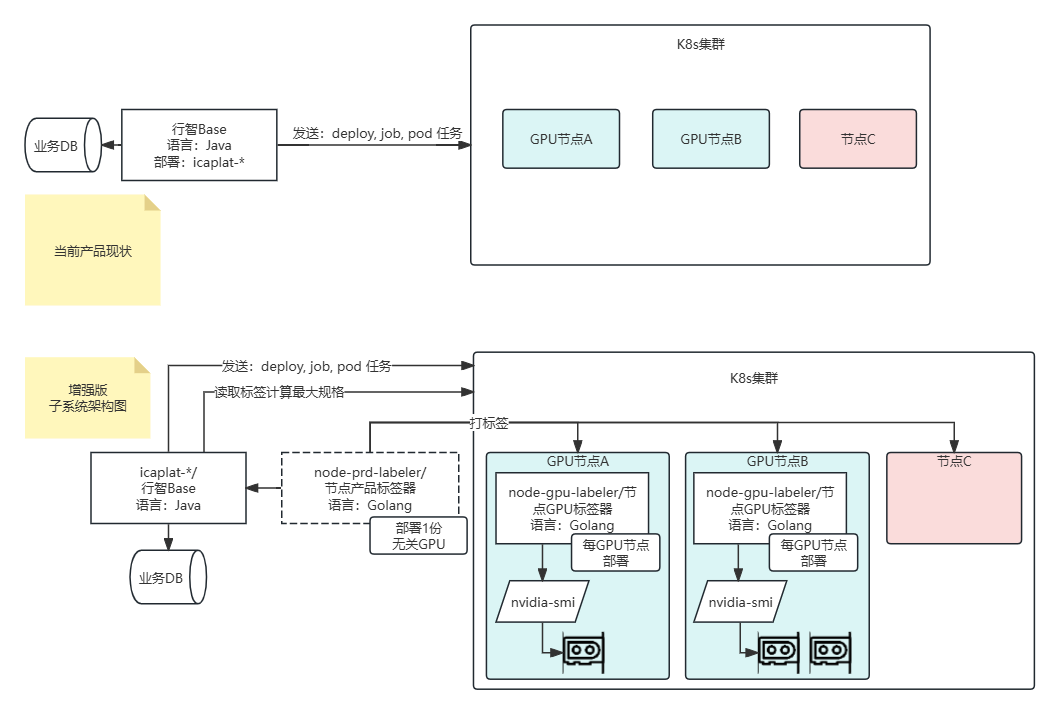
本项目为 BOE(京东方)建设的工业智能检测平台(I3Plat),采用云边端一体化架构,基于 Karmada 实现多集群统一管理。该方案已入选 Karmada 官方工业实践案例,成为业界参考标杆。
整体功能:
BOE 在液晶面板生产中引入自动缺陷分类系统(ADC),使用深度学习技术自动分类 AOI 输出的缺陷图片。I3Plat 平台实现"云"(管理+训练)+"边"(推理)+"端"(业务)的一体化方案,支持多集群统一管理、资源监控、数据分发、跨现地训练、可视化大屏等功能。
我负责的部分:
- GPU 虚拟化与调度(vCUDA 方案):基于 vCUDA 实现国产化环境下的 GPU 资源虚拟化调度,与 HAMi 类似采用 so 劫持技术,但 vCUDA 使用了 TimeSlicing 机制实现更精细的 GPU 分时复用。负责 GPU 调度核心功能的设计与实现,包括显存隔离、算力分时复用、任务队列管理等关键模块
- 多集群资源管理:参与引入 Karmada 实现多个"行智"副本的统一管理,配合团队通过聚合层 API 实现跨集群数据访问,支持中心云对所有现地集群的监控和调度
📝 本人撰写的 Karmada 官方工业实践案例 → 🏆 Karmada 官方工业实践案例 →
技术对比:
| 特性 | vCUDA(本项目) | HAMi |
|---|---|---|
| 工作原理 | so 劫持(重写 CUDA 驱动 libvgpu.so,作用于 CUDA-Runtime 和 CUDA-Driver 之间) | so 劫持(重写 CUDA 驱动 libvgpu.so,通过 LD_PRELOAD 优先加载) |
| GPU 算力方案 | 采用 TimeSlicing 分时复用机制,通过时间片轮转方式实现 GPU 算力的多任务共享,支持显式设置算力百分比 | 采用 令牌桶算法进行算力限流,拦截 cuLaunchKernel 等 Kernel 提交 API,Token 耗尽时 sleep 等待恢复;默认策略下单 Pod 不做限制以提升利用率 |
| 显存隔离方案 | 拦截 cuMemoryAllocate/cuMemAlloc_v2 等内存分配 API,增加 oom_check 检查,超过显存配额直接返回 OOM | 同样拦截内存分配 API,在分配前检查 Pod 显存使用量是否超过 Resource 申请量,超限直接返回 OOM |
参考来源:https://www.cnblogs.com/vitochen/p/18934991 - 《基于HAMi的容器GPU虚拟化》

视频展示了 vCUDA 任务调度队列的实际运行效果,多个任务排队调度,依次完成。